Comment évaluer un modèle de détection d'intrusion ?
L’évaluation d’un système de détection est un problème bien plus difficile qu’il n’y paraît. Prenons trois arguments marketing classiques, typiques des vendeurs d’IDS :
- « Détecte 99 % des menaces »
Est-ce réellement un bon argument ? Est-ce seulement une information exploitable ?
Un IDS peut-il être jugé sur ce seul chiffre ? Quid des faux-positifs ? - « Moins de 1 % de faux positifs »
Sur quel jeu de données ? Dans quelles conditions ?
En pratique, ça représente combien d’alertes par jour sur un réseau réel ? - « Trois fois plus performant que les autres IDS »
Plus performant dans quel sens exactement ?
Selon quelle métrique, quel protocole d’évaluation ?
Ces questions sont pourtant parfaitement légitimes. Mais dès qu’on les pose, la discussion dégénère rapidement en un brouillard de termes techniques : matrice de confusion, précision, spécificité, rappel, F1-score, AUC, taux de faux-positifs… Une discussion d’autant plus charabiesque que le vendeur lui-même ne comprend sûrement pas les termes qu’il emploie.
Mais ce n’est pas vraiment surprenant. Ces notions font appel à des concepts de probabilités et de statistiques qui sont objectivement difficiles, parfois contre-intuitifs. J’ai moi-même une formation en data science et en machine learning et je peine encore à raisonner correctement sur des systèmes de détection appliqués à des phénomènes rares, qui est le cas typique en cybersécurité. C’est aussi pour cette raison que j’écris cet article, pour mettre de l’ordre dans mon esprit.
L’objectif de cet article est de fournir une grille de lecture claire pour comprendre ce qu’est réellement un bon système de détection. Pas en empilant des métriques sans les comprendre, mais en reconstruisant complètement le raisonnement depuis le début. Tous les concepts seront expliqués en français, mais je vous donnerai à chaque fois leur traduction en anglais pour s’y retrouver dans la littérature anglaise.
C’est parti.
1. C’est quoi un test de détection ?
Commençons par nous donner un vocabulaire de base, pour s’assurer qu’on parle bien le même langage.
Notre objectif est de réussir à détecter un événement particulier dans un ensemble d’événements. L’événement est particulier car il a une certaine caractéristique d’intérêt, par exemple, une session réseau malveillante dans un ensemble de sessions réseau non malveillantes. Pour ce faire on confronte cet événement à un test de détection, qu’on qualifie de binaire car il n’a que deux réponses possibles : oui l’événement présente cette caractéristique ou non l’événement ne présente pas cette caractéristique. La réponse d’un test de détection est appelé une prédiction.
Lorsqu’un test fait une prédiction, il y’a 4 situations possibles :
- le test prédit que la session est malveillante et elle est effectivement malveillante ;
- c’est un vrai positif, noté VP (true positive noté TP en anglais)
- le test prédit que la session est malveillante mais elle n’est en réalité pas malveillante ;
- c’est un faux-positif, noté FP (false positive noté FP en anglais)
- le test prédit que la session n’est pas malveillante alors qu’elle est en réalité malveillante ;
- c’est un faux-négatif, noté FN (false negative noté FN en anglais)
- le test prédit que la session n’est pas malveillante et elle n’est effectivement pas malveillante ;
- c’est un vrai-négatif, noté VN (true negative ou TN en anglais)
Pour mieux s’approprier les termes retenez la logique :
- vrai / faux indique si la prédiction est correcte ou erronée ;
- positif / négatif indique si le test détecte la présence de la caractéristique d’intérêt ou son absence.
Par exemple : un vrai-négatif désigne une bonne (vrai) prédiction de l’absence (négatif) de la caractéristique.
Il est crucial de bien distinguer ces quatre situations. Toute la suite des explications dépend de cette base. Si ces termes ne sont pas clairs pour vous, aucun raisonnement ultérieur ne le sera.
2. Évaluer un test de détection : sensibilité et spécificité
On cherche maintenant à savoir si notre test est efficace. Pour ce faire, on va évaluer le test sur un ensemble d’événements déjà qualifiés de manière certaine comme malveillant ou non malveillant, et comparer les prédictions à la vérité. On dit que cet ensemble est labellisé.
Par exemple, considérons un grand jeu d’événements labellisés contenant :
- 1 000 sessions réellement malveillantes ;
- 99 999 000 sessions réellement non malveillantes.
On applique notre test à chacun des 100 millions d’événements. Chaque prédiction tombe nécessairement dans l’une des quatre catégories vues précédemment : VP, FP, FN ou VN.
Admettons qu’on obtienne les résultats suivants :
- sur les 1 000 sessions réellement malveillantes :
- 999 sont correctement détectées → 999 vrais positifs (VP) ;
- 1 n’est pas détectée → 1 faux négatif (FN) ;
- sur les 99 999 000 sessions réellement non malveillantes :
- 99 899 001 sont correctement ignorées → 99 899 001 vrais négatifs (VN) ;
- 99 999 sont incorrectement signalées comme malveillantes → 99 999 faux positifs (FP).
On peut résumer ces résultats sous la forme d’un tableau, qu’on appelle une matrice de confusion :
| Prédiction : malveillant | Prédiction : non malveillant | |
|---|---|---|
| Réalité : malveillant | VP = 999 | FN = 1 |
| Réalité : non malveillant | FP = 99 999 | VN = 99 899 001 |
Alors, est-ce que ce test est “bon” ? Comment interpréter ces chiffres ?
Sensibilité
Une première approche est de regarder la proportion d’événements réellement malveillants correctement détectés :
- = nombre de malveillants correctement détectés / nombre total de malveillants
- = VP / (VP + FN)
- = 999 / 1 000
- = 99,9 %
Cette valeur s’appelle la sensibilité (ou sensitivity en anglais) du test. Certains l’appellent aussi le rappel (ou recall en anglais). Pour ma part, je préfère le terme sensibilité. Cette valeur nous dit : lorsqu’une session est réellement malveillante, le test la détecte dans 99,9 % des cas.
Spécificité
On peut ensuite regarder la proportion d’événements réellement non malveillants correctement ignorés :
- nombre de non-malveillants correctement ignorés / nombre total de non-malveillants
- = VN / (VN + FP)
- = 99 899 001 / 99 999 000
- = 99,9 %
Cette valeur correspond à la spécificité (ou specificity en anglais) du test. Cette valeur nous dit : lorsqu’une session est réellement non malveillante, le test reste silencieux dans 99,9 % des cas.
On obtient ainsi une première interprétation des performances du test : 99,9 % de sensibilité et 99,9 % de spécificité. On est ici au premier palier de compréhension, la base pour tous les statisticiens. À ce stade, on pourrait déjà être tenté d’avancer des arguments marketing du type :
- « détecte 99,9 % des menaces » ;
- « seulement 0,1 % de faux-positifs ».
Mais on raterait en fait encore une grande partie du problème.
3. La tromperie de la prévalence et la précision
Revenons à notre matrice de confusion et essayons de la voir sous un autre angle :
| Prédiction : malveillant | Prédiction : non malveillant | |
|---|---|---|
| Réalité : malveillant | VP = 999 | FN = 1 |
| Réalité : non malveillant | FP = 99 999 | VN = 99 899 001 |
Cela vous a peut-être déjà choqué : on obtient tout de même 99 999 faux-positifs pour seulement 999 vrais-positifs ! Je peux m’amuser à calculer la proportion des résultats positifs qui sont effectivement des bonnes prédictions :
- = nombre de bonnes (vraies) prédictions positives (malveillantes) / nombre total de prédiction positives (malveillantes)
- = VP / (VP + FP)
- = 999 / (999 + 99 999)
- ~= 1 %
Autrement dit, avec notre test, seulement 1 % des prédictions positives du test (les alertes) correspondent effectivement à une session malveillante. Et 99 % des alertes sont des faux-positifs. Beaucoup moins sexy subitement.
Cette valeur, c’est la précision du test (aussi precision en anglais). On peut aussi l’appeler la valeur prédictive positive (ou PPV en anglais). Elle représente la crédibilité statistique d’une prédiction positive.
Ici la précision est faible car la prévalence de la malveillance dans l’ensemble d’événements est faible, c’est à dire que les sessions malveillantes sont très minoritaires par rapport aux sessions non-malveillantes. Ainsi, quand on génère 0.1% de faux-positifs sur plus de 99 000 000 d’événements, on génère tout de même presque 100 000 faux-positifs. Et 100 000 faux-positifs c’est largement supérieur au nombre total réel de sessions malveillantes, ce qui fait que les vrais-positifs se retrouvent noyés au milieu des faux-positifs.
Alors, qu’est-ce qui ne va pas avec notre test ? Et bien rien du tout ! Le test est très bon, il a une sensibilité et une spécificité excellentes. C’est là qu’il faut bien comprendre quelque chose de fondamental.
La qualité intrinsèque du test n’est pas le seul critère à prendre en compte pour résoudre un problème de détection. La prévalence de la caractéristique à détecter dans la donnée est aussi un paramètre. Et la prévalence change d’un ensemble d’événements à un autre. La qualité d’un test de détection dépend de la donnée sur lequel il est appliqué. Ca peut sembler contre-intuitif, c’est ce qu’on appelle le base-rate fallacy.
Oublier de penser à la précision et à la prévalence n’est pas une erreur de débutant. C’est une erreur cognitive persistante, y compris chez des ingénieurs expérimentés, dès que l’on raisonne sur des phénomènes rares. J’en parle plus en détail dans cet article : ici.
Le jeu de donnée labellisé pris en exemple ici a volontairement une prévalence faible pour mettre en avant l’importance de la précision. La précision nous indique que les valeurs de sensibilité et de spécificité de notre test, bien qu’en apparence élevées, ne sont en fait pas assez bonnes pour rendre le test pertinent sur des données avec une prévalence aussi faible. (Voir Annexe I pour une démonstration formelle).
4. Et les autres métriques ?
Revenons à notre matrice de confusion.
| Prédiction : malveillant | Prédiction : non malveillant | |
|---|---|---|
| Réalité : malveillant | VP = 999 | FN = 1 |
| Réalité : non malveillant | FP = 99 999 | VN = 99 899 001 |
Visuellement, on a déjà calculé :
- le rapport de chaque valeur par rapport à sa ligne :
- sur la première ligne VP / (VP + FN) donne la sensibilité.
- sur la deuxième ligne VN / (FP + VN) donne la spécificité.
- le rapport de chaque valeur par rapport à sa colonne :
- sur la première colonne VP / (VP + FP) donne la précision.
- sur la deuxième colonne VN / (VN + FN) donne la valeur prédictive négative (VPN) (moins importante en détection cyber, vous n’en entendrez pas souvent parler).
Petit rappel mathématique pour la suite :
- a / (a + b) = 1 - (b / (a + b))
- Autrement dit, si j’inverse uniquement la valeur du numérateur dans le calcul de la sensibilité, de la spécificité, ou de la précision, j’obtiens tout simplement le complément à 1. La nouvelle valeur obtenue n’apporte rien de nouveau, elle exprime la même chose, mais sous une autre forme.
Pour être exhaustif, on peut donc calculer tous les compléments à 1. Attention, ces nouvelles métriques n’apportent rien de plus que les 4 valeurs précédentes, mais on les retrouve parfois dans les discours des vendeurs et des statisticiens.
- FN / (FN + VP) donne le taux de faux négatifs (ou False Negative Rate (FNR) en anglais).
- = 1 - sensibilité
- FP / (FP + VN) donne le taux de faux positifs (ou False Positive Rate (FPR) en anglais).
- = 1 - spécificité
- FP / (VP + FP) donne le taux de fausses découvertes (ou False Discovery Rate (FDR) en anglais).
- = 1 - précision
- FN / (VN + FN) donne le taux de fausses omissions (ou False Omission Rate (FOR) en anglais).
- = 1 - VPN
Et voilà, on a fait le tour de toutes les métriques fondamentales qu’on peut calculer sur une matrice de confusion. Elles ont de fondamentales qu’elles expriment en fait les 4 probabilités conditionnelles possibles lors d’une prédiction (et leur complément à 1) :
- probabilité qu’une alerte sonne sachant que l’événement est malveillant (sensibilité) ;
- probabilité qu’il n’y ait pas d’alerte sachant que l’événément n’est pas malveillant (spécificité) ;
- probabilité qu’un événement soit malveillant sachant qu’une alerte a sonné (précision) ;
- probabilité qu’un événement ne soit pas malveillant sachant qu’aucune alerte n’a sonné (VPN).
Mais nous ne rentrerons pas plus en détail dans la vision probabiliste pour l’instant, nous y reviendrons une autre fois.
Dans la vraie vie, l’importance de chacune de ces métriques dépend selon la situation. La détection de fraude veut faire un minimum de faux-positifs pour ne pas sanctionner des innocents. La détection de missiles veut faire un minimum de faux-négatifs pour ne jamais rater une attaque. La détection de chips déformées dans une usine veut faire un maximum de vrais-positifs et jeter toutes les chips abîmées, quitte à jeter un tas de chips saines par erreur au passage. Un filtre antispam veut faire un maximum de vrais-négatifs et ne bloquer aucun mail légitime, quitte à laisser passer du spam.
On peut modéliser ces préférences avec de nouvelles métriques qui combinent nos 4 métriques fondamentales, on peut alors obtenir : exactitude, F1-score, MCC, balanced accuracy, kappa, net benefit, expected utility, etc… Les possibilités sont presque infinies.
Dans notre cas on va s’intéresser uniquement au F1-score, qui est de loin le plus utilisé. L’idée du F1-score est de donner une importance égale à la sensibilité et la précision, et d’ignorer la spécificité. De plus, on veut fortement pénaliser les situations où l’une des deux valeurs est très faible. L’outil mathématique pour cela est la moyenne harmonique de la sensibilité et de la précision :
- F1-score = (2 * précision * sensibilité) / (précision + sensibilité)
Dans notre exemple on obtient :
- F1-score = (2 * 0.01 * 0.99) / (0.01 + 0.99)
- F1-score = 0.02
On obtient un F1-score très faible, cohérent avec notre mauvaise précision.
5. Conclusion pratique
Résumons ce qu’on doit retenir sur les métriques que l’on vient d’apprendre :
- La spécificité et la sensibilité sont insensibles à la prévalence. Ce sont des mesures du test lui même.
- La sensibilité mesure la capacité de mon test à détecter des vrais positifs par rapport aux faux négatifs. Une sensibilité parfaite indique que le test ne fait aucun faux-négatif. Mais la sensibilité ne dit rien sur les faux-positifs.
- La spécificité mesure la capacité de mon test à remonter les vrais négatifs par rapport aux faux positifs. Une spécificité parfaite indique que mon test ne fait aucun faux positif. Mais la spécificité ne dit rien sur les faux négatifs.
- La précision mesure la crédibilité des alertes en pratique. La précision dépend de la prévalence de la caractéristique à détecter dans la population. La précision peut donc varier selon les données sur lesquelles le test est appliqué. Une précision annoncée par un vendeur ne veut rien dire pour vos données à vous.
- Même un test intrinsèquement très bon, avec une très bonne spécificité et sensibilité, peut obtenir une précision très faible lorsque la prévalence est très faible.
Maintenant qu’on comprend bien nos métriques, on peut en tirer les conclusions pratiques suivantes :
- On veut une bonne sensibilité, car on ne veut pas faire de faux-négatifs. On veut rater un minimum de menaces.
- On veut une bonne précision, car je ne veux pas qualifier des milliers de faux-positifs par jour. Attention, la précision est spécifique à un jeu de donnée, on doit calculer nous-même la précision du test sur nos propres données (en faisant une hypothèse sur la prévalence). La précision obtenue sur un autre jeu de donnée n’est pas directement transposable à notre situation.
- La spécificité est moins directement exploitable, elle est surtout utile pour expliquer et mieux comprendre la valeur de la précision observée.
Ces conclusions pratiques sont en fait alignés avec le F1-score, qui est donc une métrique pertinente dans notre domaine. Cependant, n’hésitez pas à toujours aller jeter un œil à la sensibilité et la précision cachées derrières.
6. Ouverture sur l’éternel problème de la prévalence
Sur nos données labellisées, dans lesquelles la prévalence de la malveillance est très faible, on obtient une mauvaise précision, et donc un mauvais F1-Score. Mais alors, comment on résout ce problème de la prévalence ? comment on peut s’assurer d’avoir un test qui aura une bonne précision malgré une faible prévalence dans les données ?
La réponse mathématique est simple : il faut que le test ait une spécificité extrêmement élevée. C’est en fait le principe de la détection à base de signature, on fait des règles tellement précises qu’elles ont réellement une spécificité très proche de 1, mais uniquement pour un type d’événement très précis.
Dans le domaine de la détection d’intrusion plus généraliste, la prévalence des événements malveillants est toujours très faible. Extrêmement faible. Parfois même, elle est nulle. Et donc, même avec d’excellentes valeurs de sensibilité et de spécificité, la précision est souvent très faible, et on se retrouve noyés dans les faux-positifs.
Un bon moyen de se rendre compte du problème est de faire un graphique. A faible prévalence, la sensibilité a en fait peu d’impact sur la précision (voir Annexe I), disons qu’on la fixe à 99%. On va ensuite regarder comment évolue la précision en fonction de la spécificité (entre 98 et 100%) pour des valeurs faibles de prévalence (entre 0 et 0.1%).
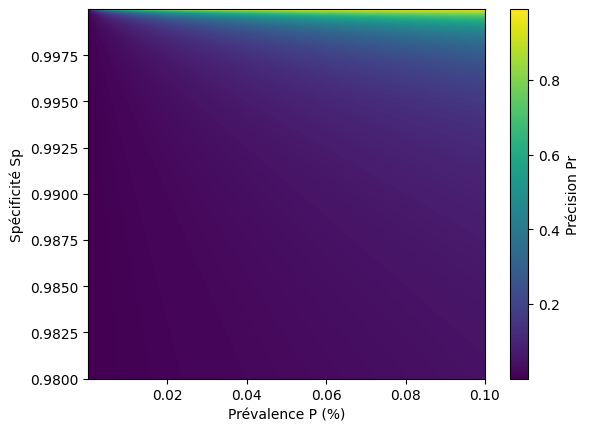
Sur ce graphe, la zone en vert-jaune correspond aux couples (P, Sp) pour lesquels la précision devient acceptable. On observe que cette zone n’apparaît que pour des valeurs de spécificité extrêmement élevées. Si élevées en fait, qu’elles sont complètement irréalistes dans la vraie vie.
On arrive à une conclusion inconfortable : il est aujourd’hui irréaliste d’imaginer un système de détection généraliste, appliqué événement par événement, qui atteigne une spécificité suffisante pour avoir une bonne précision à faible prévalence. La seule solution n’est donc pas d’améliorer le test, mais de réduire ses ambitions. Peu importent vos chiffres de sensibilité et de spécificité, vous n’aurez réalistement jamais une bonne précision. Vous n’aurez jamais de système magique qui détecte toutes les attaques sans faire des milliers de faux-positifs.
7. Qu’est-ce qu’on fait alors ?
Honnêtement ? Je ne sais pas vraiment. L’objectif de cet article était seulement d’avoir tous les outils pour prendre conscience du problème.
Mais on continuera d’explorer la question dans le prochain article : La détection d’intrusion sous l’angle du théorème de Bayes
ANNEXE I
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
Pour mieux comprendre les liens, on va exprimer la précision comme fonction de la sensibilité, de la spécificité et de la prévalence (sans faire encore appel à aucune notion de probabilités).
Soit N le nombre total d'événements. Soit P la prévalence. Soit Sp la spécificité du test. Soit Se la sensibilité du test. Soit Pr la précision.
On sait que :
- (1) total des événements malveillants = P * N = VP + FN
- (2) total des événements non-malveillants = (1 - P) * N = VN + FP
On commence par retourner les formules de Se et Sp pour définir VP et FP en fonction de P et N.
# Expression de VP à partir de Se = VP / (VP + FN) :
VP = Se * (VP + FN)
(3) VP = Se * P * N
# Expression de FP à partir de Sp = VN / (VN + FP) :
Pour servir d'intermédiaire, on pose d'abord :
VN = Sp * (VN + FP)
(4) VN = Sp * (1 - P) * N d'après (2)
Pour servir d'intermédiaire, on pose une tautologie :
FP = (VN + FP) - VN
Et on remplace :
FP = ((1 - P) * N) - (Sp * (1 - P) * N) d'après (2) et (4)
(5) FP = (1 - P) * N * (1 - Sp)
# Expression de la précision
Pr = VP / (VP + FP)
= Se * P * N / (Se * P * N + ((1 - P) * N * (1 - Sp))) d'après (3) et (5)
= Se * P / (Se * P + (1 - Sp) * (1 - P))
Dans la cyber, P est souvent proche de 0. Pour mieux comprendre la formule autour de 0 on peut simplifier le dénominateur pour P~=0, et garder en tête que le numérateur sera toujours une valeur très faible :
Pr ~= Se * P / (1 - Sp)
Conclusion :
- la précision est très sensible à la prévalence ;
- à faible prévalence, la précision dépend fortement de Sp et très peu de Se.